本文不考虑和top合并, 并且大小非fastbin。实际做题的时候得要考虑top。
free时overlap
poison_null_byte
P(P是size被null的块)|Q
需要构造的点:
1. chunksize(P) == prev_size (next_chunk(P)) //因为offbyone后的size一定<=原始size,所以prev_size (next_chunk(P)) 可以自己伪造
2.free(P)后分割P为块A和B A|B,此时Q的pre_inuse也为0了
3.free A,free Q,A和Q会 consolidate, B就被overlap了注意 free 的时候
- 检查前一个chunk空闲吗(检查本块的prev_inuse)
- 检查后一个是不是top chunk
- 检查后一个chunk空闲吗(nextinuse = inuse_bit_at_offset(nextchunk, nextsize);)这种方法利用的点就在于free Q的时候,glibc2.23 没有检查 prev_size(Q) == chunksize(pre_chunk(Q))
glibc2.23: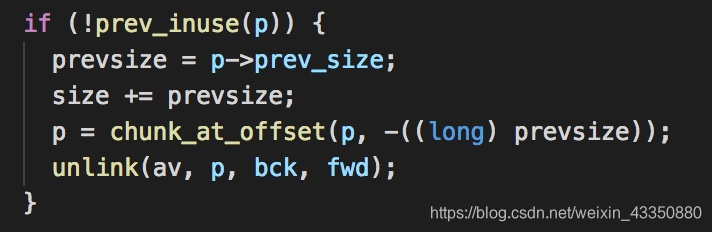
glibc2.29是要检查的了(我看的在线版是2.29而已),此时这个利用方法就失效了。
CTFWiki5:通过extend前向overlapping
通过修改pre_inuse域和pre_size域实现合并前面的块
int main(void)
{
void *ptr1,*ptr2,*ptr3,*ptr4;
ptr1=malloc(128);//smallbin1
ptr2=malloc(0x10);//fastbin1
ptr3=malloc(0x10);//fastbin2
ptr4=malloc(128);//smallbin2
malloc(0x10);//防止与top合并
free(ptr1);
*(int *)((long long)ptr4-0x8)=0x90;//修改pre_inuse域
*(int *)((long long)ptr4-0x10)=0xd0;//修改pre_size域
free(ptr4);//unlink进行前向extend
malloc(0x150);//占位块
}和 poison_null_byte 的区别在于:本例中pre_inuse(Q)和pre_size(Q)都是自己伪造的,而 poison_null_byte 是free(P)得到的。
overlapping_chunks(向高地址合并)
A|B|C
A的size改为A+B的size
free(A)
malloc(sizeof(A+B)) 即可overlap B
overlapping_chunks_2
A|B|C
A的size改为A+B的size
free( C )
free( A )
malloc(sizeof(A+B+C))
B就被overlap了
house_of_einherjar
首先看后向合并(向低地址合并)的代码
if (!prev_inuse(p)) {
prevsize = prev_size(p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd);
}house_of_einherjar的关键就在于绕过unlink的检查:
P(内部伪造了假块p)|Q(被nullbyte)
1. 利用 unlink 漏洞的时候:
p->fd = &p-3*4
p->bk = &p-2*4
在这里利用时,因为没有办法找到 &p , 所以直接让:
p->fd = p
p->bk = p
2. chunksize(p) != prev_size (next_chunk(p)) next_chunk是根据p的size算的,也就是说只要p偏移size处的值为size即可。
3. Q的pre_inuse位为0,prev_size(Q)需覆盖到p的头部,free(Q)即可获得prev_size(Q)+sizeof(Q)的空闲chunk和poison_null_byte及CTFWiki5的区别就在于,free后向低地址合并的时候,house_of_einherjar低地址的块是自己伪造的,而poison_null_byte低地址的块是free来的。
其实poison_null_byte低地址的块也可以自己伪造。对于P|Q,poison_null_byte是P被nullbyte,而且是先free(P),再nullbyte,所以保留了pre_size(Q),nullbyte后构造假的pre_size(nextchunk(P)),free(Q)即可获得P+Q。例子里是把P给分成了A|B(因为P的size已经被nullbyte了,所以怎么分都不会再影响pre_size(Q)),然后free A,以在free(Q)的时候绕过unlink检查,当然也可以通过伪造来绕过size和unlink检查,构造以下条件即可:
*(size_t*)(b1+0x100) = 0x110;//chunksize(A) != prev_size (next_chunk(A))
*(size_t*)(b1) = (size_t*)(b1-0x10);//FD->bk != P || BK->fd != P
*(size_t*)(b1+0x8) =(size_t*) (b1-0x10);当然分为A和B也有好处,这样能够overlap B,控制B的所有信息。
以上是比较保守的做法,how2heap里的就相对大胆:在栈里伪造一个假的freed的chunk,把prev_size(Q)改为nullbyte了的块的地址-栈中假chunk的地址,free(Q)后获得了在栈上malloc块的机会。
malloc时overlap
CTFWiki3:对free的smallbin进行extend
int main()
{
void *ptr,*ptr1;
ptr=malloc(0x80);//分配第一个0x80的chunk1
malloc(0x10);//分配第二个0x10的chunk2
free(ptr);//首先进行释放,使得chunk1进入unsorted bin
*(int *)((int)ptr-0x8)=0xb1;
ptr1=malloc(0xa0);
}